- Published on
Case study: Build A Custom ChatGPT Bot
- Authors

- Name
- Chao Wu
- @chaobuilds
I recently completed a consulting project in partnership with Michael Lin to build a custom ChatGPT bot for a client.
Our client is a workforce analytics consultant who compiled a folder with past research, notes, PDFs, statistics, and URLs on workforce data.
The client needed a way to quickly query information from their research and generate reports, but was manually CMD+F through the folder for relevant results and including it in their reports, a very time-consuming process. They also wanted to use this tool to generate job recommendations for their clients.
Since OpenAI provides API access to ChatGPT models (GPT-3.5-turbo, GPT-4), this type of problem can be perfectly solved by building a ChatGPT bot that analyzes custom data.
Tech Stack

- Frontend: Next.js
- Backend: Flask + LangChain
- Data Storage: AWS RDS + S3 + Pinecone
Chatbot Components
The tool consisted of 3 main parts:
- The chatbot that the client could ask questions to
- An admin panel for uploading files and URLs to the knowledge base
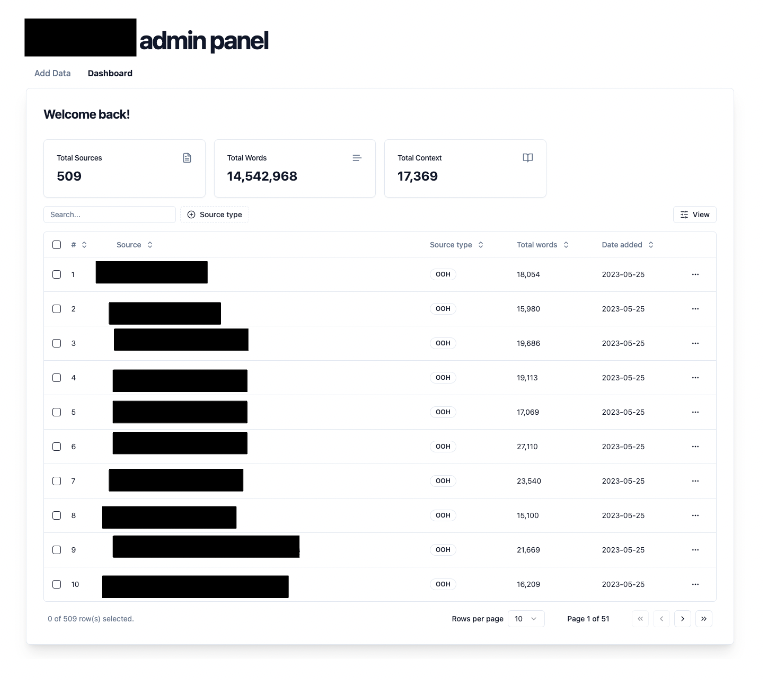
- A dashboard for managing the uploaded context in the knowledge base
The front end was built using one of the AI Chatbot templates provided by Vercel.
The backend tool we built used a combination of LangChain for processing the various file types as context and Pinecone for storing embeddings.
Screenshots are below:
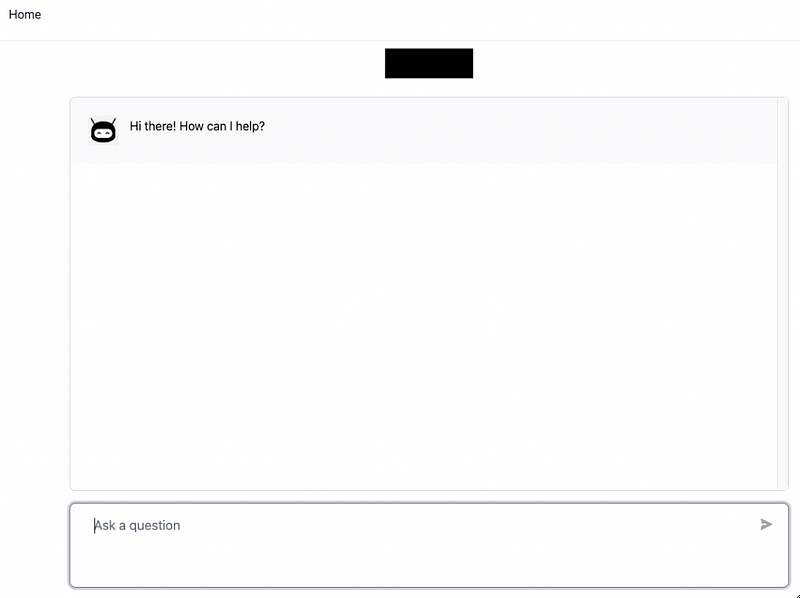
Chatbot
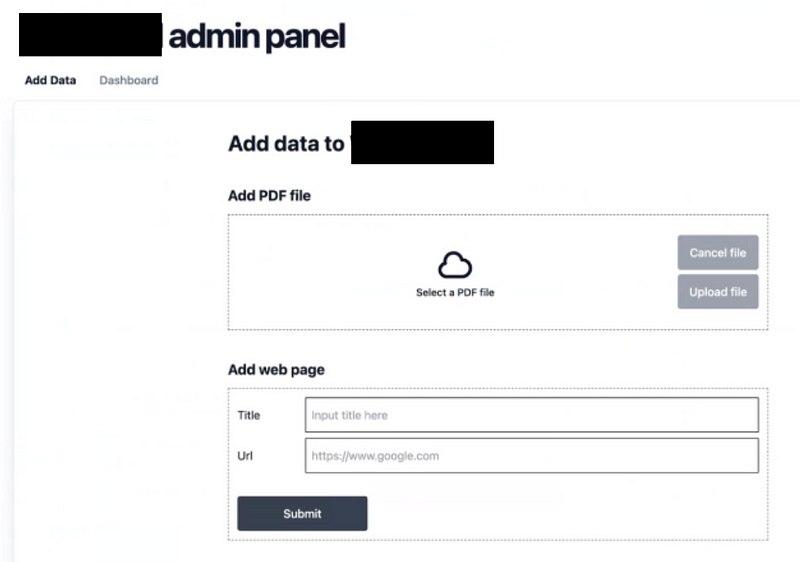
Admin Panel
Dashboard
How the Tool Works
The flow for this tool is as follows:
- The client uploads all of their files, notes, and bookmarked web pages using the admin panel we built for them
- We parse and store these as embeddings in Pinecone vector DB
- When the customer asks a query, we first turn their query into a vector and run a similarity search within Pinecone DB to find vectors that are most similar as contexts.
- We return all vectors over the threshold we set for a similarity match
- We then augment their query with our own prompts & additional LLM chaining if needed to be more specific about the kind of responses we are looking for
- We return the answer with source context links for the user to cross reference
Key Insights
URL Handling
When it comes to handling URLs for context, the client had a common misconception that we could just pass ChatGPT a URL in a prompt, and it would parse the website's content for us.
This is actually incorrect. For example, if you ask it, "Give me the data from <insert url> about how much a teacher makes per year", and it returns the right data, it's often just a coincidence that the data it returns is the same from the website.
It could also be that that website was part of the initial training set for ChatGPT, hence why it returns the same response.
However, it did NOT actually crawl the website in real-time to return that response.
One way to prove this is if you ask it a query like: "Summarize this story: https://www.nytimes.com/2021/03/10/business/angry-fans-demand-nickelback-refunds.html"
ChatGPT will actually return a summary, even though if you go to that website, it actually leads to a 404.
To get around this, you have to use web scraping APIs to access the content of a URL first, and then pass that text as context to ChatGPT.
And then even after scraping the data, you often have to "clean" the data because as is, it may contain unnecessary tags or is poorly formatted, which makes it harder for ChatGPT to understand.
Fortunately, LangChain has APIs where you can pass in URLs that handle this processing and ingestion for you, which should be used instead.
Data Privacy
The client also asked a question about whether or not the context they passed into OpenAI will be used to train OpenAI's models or not.
As of March 1st, 2023, Open AI has made it clear in their TOS that data passed through their API will NOT be used in their training set
The data is only retained to monitor for abuse for 30 days, after which it is deleted.
However, the data passed to non-API consumer services like ChatGPT or Dall-E MAY be used to improve their models.
It is possible to request to opt out of this for ChatGPT by turning off Chat History. You can see a screenshot of their API data usage policy as of 7/18/23: 
Relevant data policy links: